금융시스템 대량 데이터 처리
금융 OLTP 환경에서 안정적으로 대량 요청을 처리하기 위한 캐시·제약사항·비동기 방안과, 대량 거래를 자동 반복 처리하는 센터컷 아키텍처를 DevOn Framework 관점에서 정리한다.
20세기 은행이나 보험, 증권사와 같은 금융 회사를 방문하여 창구를 통해 금융서비스를 제공 받았던 시절과는 달리 지금은 모바일 기기의 확산, 광대역 통신망의 보급, H/W·S/W 수준의 향상에 힘입어 언제 어디서나 많은 사용자들이 금융서비스를 제공받고 있습니다.
이에 더해 인터넷 뱅킹사업자의 출현 및 오픈 뱅킹이 확산됨에 따라 서비스 사용량은 훨씬 증가하게 되었습니다.
은행을 비롯해 그 외 다른 금융시스템은 모두 대량의 서비스 요청에 대비한 대량 데이터 처리 기능을 갖춰나갔고 금융 시스템 중 계정계, 기간계 등 주요 시스템의 프레임워크의 역할이 중요해졌습니다.
이번 글에서는 금융시스템에서 대량 데이터 처리를 위해 사용하는 다양한 방안을 설명하고 이를 위해 DevOn Framework가 제공하는 솔루션을 소개합니다.
1. OLTP 대량 처리를 위한 방안
여러 채널 및 직원 단말화면에서 실시간으로 들어오는 대량의 온라인 요청을 처리하는 계정계, 기간계 시스템을 대비하여 프레임워크에서 제공하는 방안을 설명합니다.
1.1 데이터 캐시 처리
온라인 요청을 처리하기 위한 시스템에서 코드나 메시지 등 공용 데이터를 반복적으로 DB Table에서 조회하는 경우, 이를 속도가 빠른 Cache 메모리 영역에 보관해 두었다가 필요 시 제공하여 성능상 이점을 취하는 방식입니다.
캐시는 저장하는 위치에 따라 종류를 아래와 같이 구분합니다.
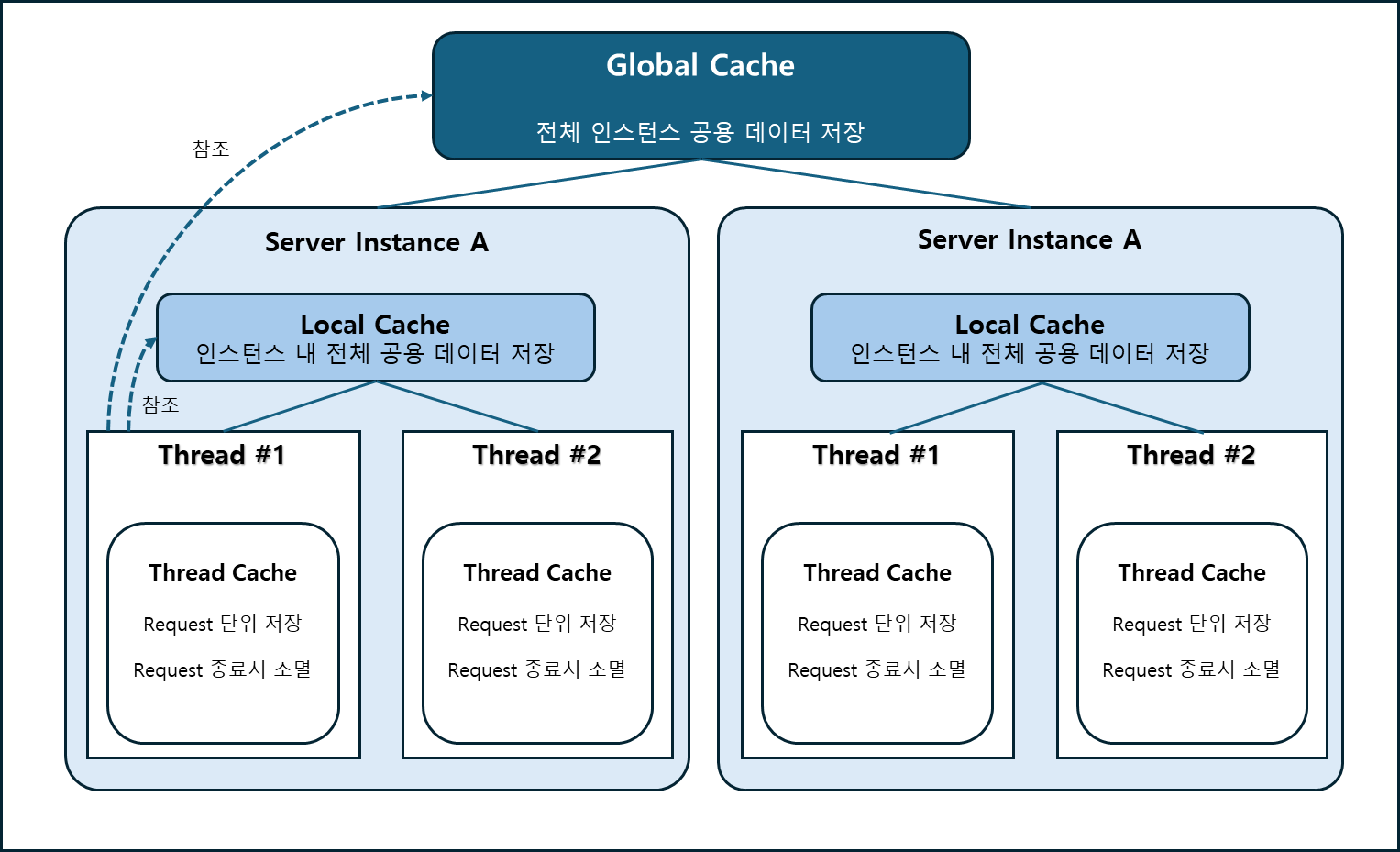 [캐시 종류별 계층 구조]
[캐시 종류별 계층 구조]
| 구분 | Thread Local | Local | Global |
|---|---|---|---|
| 범위 | 단일 요청 | 단일 인스턴스 | 전체 서버 |
| 속도 | 가장 빠름 | 빠름 | 상대적으로 느림 |
| 일관성 | 완전 보장 | 인스턴스 간 불일치 가능 | 보장 |
| 용량 | 매우 작음 | 중간 | 대용량 가능 |
| 생존 주기 | 요청 종료 시 소멸 | 인스턴스 재시작 시 소멸, Refresh 시 갱신 | 별도 TTL 설정 |
| 주요 기술 | ThreadLocal | Caffeine · EhCache | Redis · Memcached |
1) Thread Local Cache
- 단일 요청 내 기준 정보로 사용되는 데이터 및 동일 쿼리 호출 방지용 데이터
- 예: 지점·사원·화면·거래 ID 등 전문 HEADER에 포함된 기준 정보를 반복 사용하는 경우, 주문 처리 중 동일 사용자 정보를 여러 모듈에서 반복 조회하는 경우
2) Local Cache
- 변경이 드물고 모든 인스턴스가 동일하게 사용하는 데이터
- 예: 공통 코드, 거래 파라미터, 메시지 코드값 등
3) Global Cache
- 인스턴스 간 반드시 동일해야 하는 공유 데이터
- 예: 세션 클러스터링 등
※ DevOn Framework의 제공 솔루션
위에서 설명한 캐시 기능을 DevOn Framework에서 어떤 방식으로 제공하고 있는지 살펴보겠습니다.
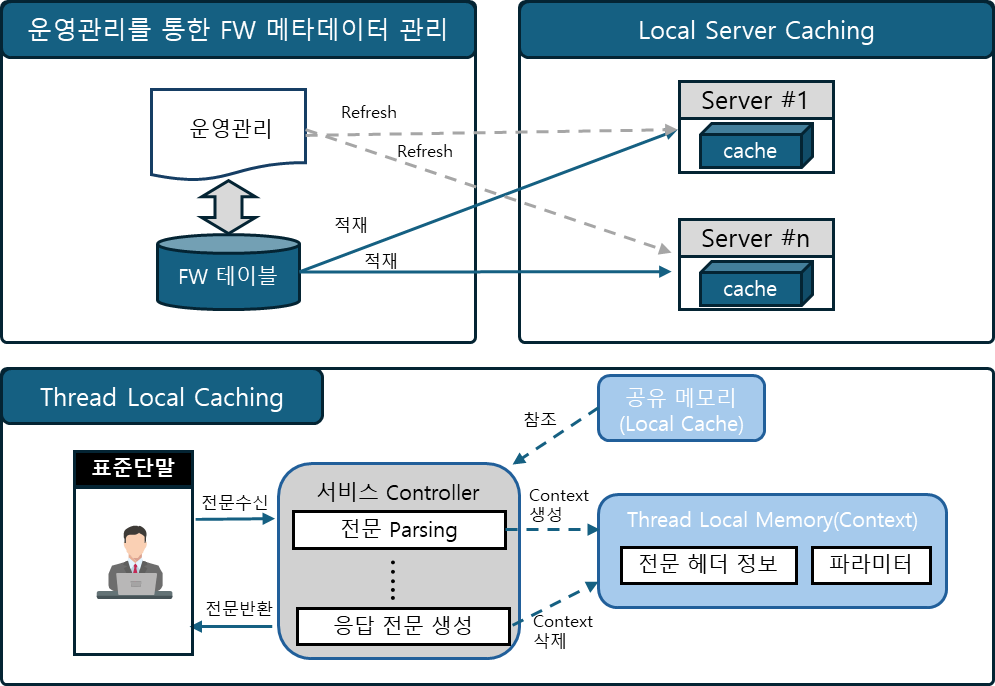 [DevOn Framework Cache 구성]
[DevOn Framework Cache 구성]
A. Local Cache 기능
기본적으로 각 서버별 로컬 캐시를 통해 프레임워크 파라미터와 같은 Thread와 무관한 공용 데이터를 로컬 캐시에 저장하여 관리합니다.
해당 캐시 정보는 프레임워크 운영관리 화면에서 편리하게 관리할 수 있으며, 내용이 갱신되는 경우 서버 재시작 없이 Refresh 할 수 있도록 구성되어 있습니다.
B. Thread Local Cache 기능
각 요청을 처리하는 Thread의 전 과정에서 자주 사용하는 정보들을 Context라는 개념으로 ThreadLocal에 저장하여 사용하고, Thread가 종료되면 자동으로 소멸시켜 불필요한 메모리 사용이 발생하지 않도록 관리합니다.
위 기능들은 기본적으로 프레임워크에서 관리되어 업무 어플리케이션에서는 별도로 처리하지 않아도 캐시 기능을 자동으로 활용할 수 있습니다.
C. Global Cache 기능
Global Cache는 프로젝트마다 필요에 따라 기능을 생성하며, 보통 클라우드 환경에서 Redis를 통해 Session 정보를 공유해야 하는 경우 많이 활용하고 있습니다.
1.2 OLTP 제약사항 정의
금융 시스템에서 원활하게 온라인 요청을 처리하기 위해서는 제공하는 서비스에 일정 부분 제약 사항이 필요합니다. 특정 서비스가 온라인 시스템의 Resource를 모두 독점하여 시스템 안정성을 해치는 리스크를 방지하기 위해서입니다.
대량의 데이터를 처리할수록 하나의 서비스가 시스템 Resource를 과점유하는 것이 큰 여파로 다가올 수 있습니다. 이번 장에서는 발생할 수 있는 Resource 과점유 케이스를 살펴보고, 이를 위해 DevOn Framework에서 제공하는 제약사항 기능을 살펴보도록 하겠습니다.
1) 과도한 조회 쿼리 남용
첫 번째로 SELECT SQL에서 너무 많은 데이터를 조회하여 문제를 유발하는 경우입니다.
- 조회 기간에 제한 없이 조회용 서비스를 제공하는 경우
- 예: 법인 고객 A의 3년치 계좌 거래내역 조회 등
- 페이징 처리를 사용하지 않고 전체 조회를 수행하는 서비스의 경우
- 예: 고객 정보를 조회하며 보유한 계좌 전체를 보여주는 화면에서, 보유 계좌가 수천 개에 이를 가능성을 예상하지 못한 경우
- LIKE 검색을 허용하는 광범위한 조건 검색이 가능한 서비스를 제공하는 경우
- 예: 고객 이름 검색 기능에서 글자 수 제한을 두지 않아 "김", "이" 등 다수 성씨로 조회하는 경우
위와 같이 잘못 설계된 프로그램이 실행되는 경우, 서비스 프로그램의 SELECT SQL이 너무 많은 데이터를 조회하게 되어
- DB Connection 반환 시간 지연으로 인한 고갈
- DB 데이터 버퍼의 메모리 과다 점유
- 응답 시간 지연
등의 문제가 발생해 시스템 안정성을 저해할 수 있습니다. SELECT SQL로 조회할 수 있는 건수를 프레임워크에서 제약할 필요가 있습니다.
2) 객체의 과도한 메모리 적재
JVM 인스턴스 내에서 동작하는 Java Web Application은 JVM에 설정된 Heap 메모리를 초과하여 데이터를 적재할 수 없으므로, 아래와 같은 잘못된 Application에서는 문제를 발생시킬 수 있습니다.
- 조회된 SQL 데이터의 병합 처리
- 예: 당해년도 이자 계산을 위해 각 월별 거래내역을 조회하여 하나의 객체에 추가하는 경우
- 중첩 LOOP문을 통한 데이터 적재
- 예: 고객별 우대금리 적용 대상자 조회 프로그램에서 고객·상품별 대상 항목을 적재하는 경우, 고객과 상품 각각의 건수는 크지 않더라도 중첩 LOOP로 인해 n × m의 결과가 발생하여 대량 데이터 적재로 이어짐
이런 과도한 메모리 적재는 OOM을 발생시켜 금융시스템 안정성에 문제를 일으키므로 다음과 같은 데이터 적재 제약이 필요합니다.
- 업무 Application에서 사용하는 데이터 Collection 종류 제약
- 프레임워크에서 데이터 적재를 제약하기 위해서는 사용 가능한 Collection Object의 제약이 선행되어야 함
- 데이터 Collection의 적재 건수 제약
- 프레임워크에서 Collection Object를 Overriding하여 데이터 건수를 시스템 규모에 맞게 제약
3) 서비스 처리시간의 과도한 점유
Java Web Application에서 단일 서비스가 과도하게 긴 시간 동안 실행될 경우, 해당 서비스가 Thread와 DB 커넥션을 장시간 점유하게 되어 문제를 발생시킬 수 있습니다.
- 타임아웃 미설정으로 인한 무제한 실행
- 예: 전체 고객의 월말 이자 계산 서비스에서 종료 조건 없이 수백만 건의 데이터를 순차 처리하는 경우, 단일 서비스가 수 시간 동안 Thread를 점유하여 Thread 및 DB Connection 등의 자원이 고갈되는 문제 발생
- 중첩 루프문으로 인한 실행 시간 폭증
- 예: 고객별 우대금리 대상자 선별 프로그램에서 고객 수와 상품 수가 각각 크지 않다고 판단했으나 중첩 루프(n × m) 내부에서 매 건 DB 조회가 발생하여 실행 시간이 개발 환경 대비 수백 배 이상 증가하는 경우
이러한 서비스 실행 시간의 과도한 점유는 Thread 고갈 및 DB 커넥션 소진을 유발하여 금융시스템 전체 서비스 중단으로 이어질 수 있으므로 다음과 같은 실행 시간 제약이 필요합니다.
- 서비스 단위 실행 시간 상한 설정
- 프레임워크에서 서비스별 최대 허용 실행 시간을 사전에 정의하여 초과 시 중단하는 메커니즘 필요
- 서비스 실행 시간 모니터링 기능
- 온라인 요청에서 수행된 서비스의 수행시간 이상 여부를 파악하기 위한 모니터링 기능 필요
※ DevOn Framework의 제공 기능
DevOn Framework는 대량 처리 온라인 시스템의 안정성 보장을 위해 다음과 같은 제약사항을 설정할 수 있습니다.
A. SQL 처리건수 제약
프레임워크에 설정된 Max Fetch Count를 초과하여 SELECT SQL 데이터가 조회된 경우, ResultSet에서 Data Transfer Object로 변환할 때 이를 체크하여 오류를 발생시키며 해당 서비스는 에러를 반환합니다.
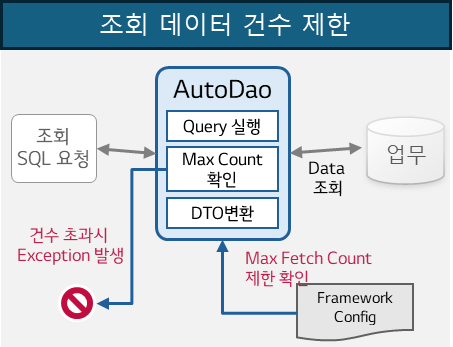 [조회 건수 제한 처리 방식]
[조회 건수 제한 처리 방식]
이런 제약사항의 설정을 통해 서비스의 무분별한 메모리 점유를 방지하여 시스템 안정성을 높입니다. 전체 SQL에 대한 제약이 가능하며, 필요한 경우 SQL별 건수 제한도 제공합니다.
B. 최대 List 건수 제한
DevOn Enterprise Framework는 내부 DTO(Data Transfer Object)로 자체 개발한 Map과 List를 사용하여 처리하도록 제한되어 있습니다.
특히 다건을 적재하기 위한 List는 Max Count를 설정하고, 이를 초과하여 적재하는 경우 오류가 발생하도록 구현되어 있습니다.
 [최대 List 건수 제한 처리 방식]
[최대 List 건수 제한 처리 방식]
업무 Application은 별도의 객체를 사용하지 못하도록 개발 단계에서 정적 inspection을 통해 제한하고 있으며, 표준 List 개체의 건수 제약을 통해 Out of Memory를 방지하고 Major GC 발생을 최소화하고 있습니다.
C. 서비스 Timeout 설정
DevOn Enterprise Framework의 서비스는 DB에 적재되는 파라미터 정보를 기반으로 실행되며, 이 정보 중에는 서비스별 Timeout 정보도 포함되어 있습니다.
해당 정보는 프레임워크 운영관리 화면을 통해 관리하고 실시간으로 변경 적용할 수 있습니다.
서비스 내에서 DB SQL을 실행할 때마다 매번 서비스 수행시간이 설정된 Timeout을 초과하였는지 체크하며, 초과한 경우 오류를 발생시켜 서비스를 중단시킵니다.
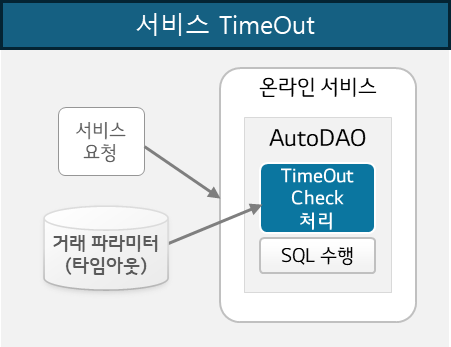 [서비스 Timeout 처리 방식]
[서비스 Timeout 처리 방식]
서비스별 Timeout을 설정하면 특정 서비스에 의해 시스템 Resource가 점유되는 현상을 방지할 수 있어 대량 온라인 처리 시스템의 안정성을 향상시킬 수 있습니다.
또한, DevOn에서 제공하는 운영관리의 거래 로그 화면에서는 조회 조건에서 특정 시간 이상 소요된 거래를 선택할 수 있어 Timeout 문제 해결에 도움을 줍니다.
1.3 비동기 처리 지원
온라인 시스템은 사용자의 요청에 즉각 반응해야 하는 만큼, 빠른 응답 시간은 선택이 아닌 필수입니다. 이를 위한 여러 최적화 방법 중 하나가 바로 비동기 처리 방식입니다.
비동기 처리란, 요청을 보낸 후 응답을 기다리지 않고 다음 작업을 즉시 수행하는 방식입니다. 기다리는 시간 없이 처리를 이어나갈 수 있어 전체 응답 시간을 단축하는 데 효과적입니다.
물론 비동기 방식으로 인해 처리 흐름이 분기되고 결과를 나중에 처리해야 하므로 코드의 복잡도가 높아지고, 그만큼 시스템 유지보수의 난이도도 올라갑니다.
그럼에도 불구하고 대기 시간을 줄여 처리량을 끌어올려야 하는 대량 처리 시스템의 요구에 부응하기 위해 비동기 방식은 폭넓게 활용되고 있습니다.
다음은 업무 프로그램에서 응답 속도를 높이기 위해 많이 사용하는 비동기 처리 방식에 대해 살펴 보겠습니다.
멀티 모듈 동시 호출 방식
업무 모듈의 로직 중 다른 다수의 모듈을 호출한 후 그 결과를 통합하여 다음 작업을 진행하는 경우, 모든 모듈의 호출이 순차적으로 이루어지므로 처리 시간이 많이 소요됩니다.
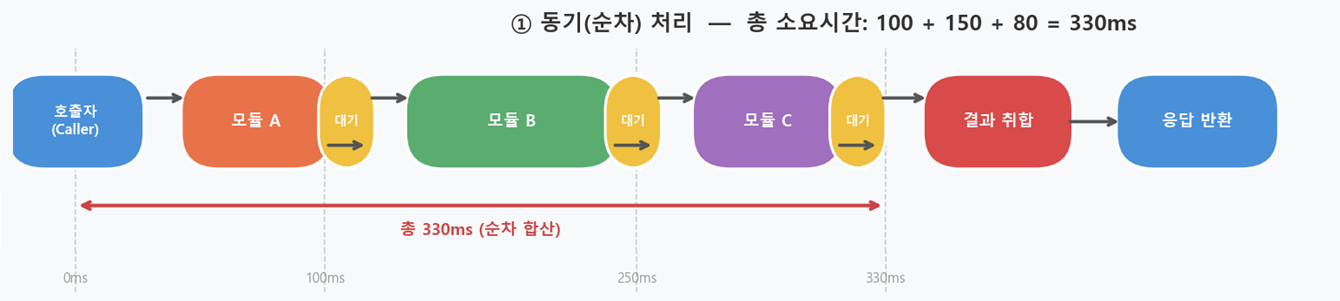 [동기 순차 처리]
[동기 순차 처리]
모듈 호출을 비동기 방식으로 처리할 수 있다면 어떻게 될까요. 다음과 같이 응답 시간이 변경될 수 있습니다.
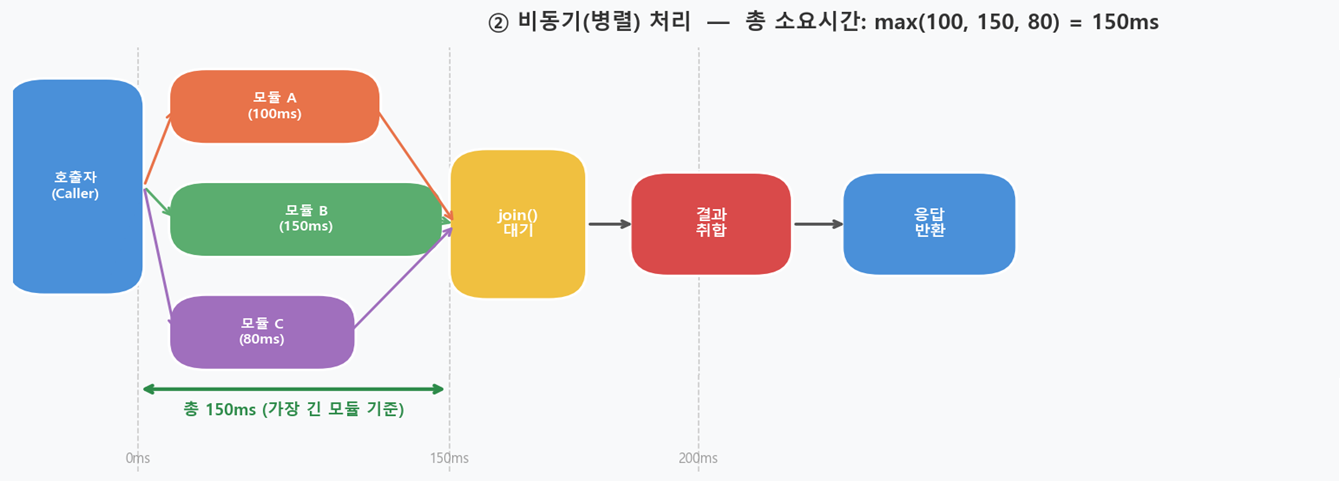 [비동기 병렬 처리]
[비동기 병렬 처리]
중간에 호출되는 모듈 A·B·C 중 가장 긴 응답시간을 가지는 모듈 B의 응답시간만큼만 소요되어 전체 응답시간이 줄어드는 효과를 볼 수 있습니다.
※ DevOn Framework의 제공 기능
DevOn Enterprise Framework에서는 비동기 멀티 호출을 지원하기 위해 다음과 같은 기능을 제공합니다.
A. 비동기 서비스 연동 기능 제공
프레임워크 파라미터 중 타 서비스 모듈을 호출하기 위한 연동 파라미터 값이 있습니다. 이 파라미터 항목 중 '동기/비동기'를 선택할 수 있는 항목이 있으며, 설정된 항목값에 따라 서비스 호출 방식이 결정됩니다.

위와 같이 화면을 통해 입력된 설정값에 따라 프레임워크가 비동기 방식으로 알아서 호출해 주므로 업무에서 별도 처리는 불필요합니다.
B. 호출 응답값 획득용 API 제공
위에서 살펴본 것처럼 비동기 멀티 호출 방식은 결과값을 모아야 할 필요가 있습니다. 비동기 처리 모듈에 대한 결과값 획득은 내부적으로 Java Future 클래스를 이용하는 API를 제공합니다.
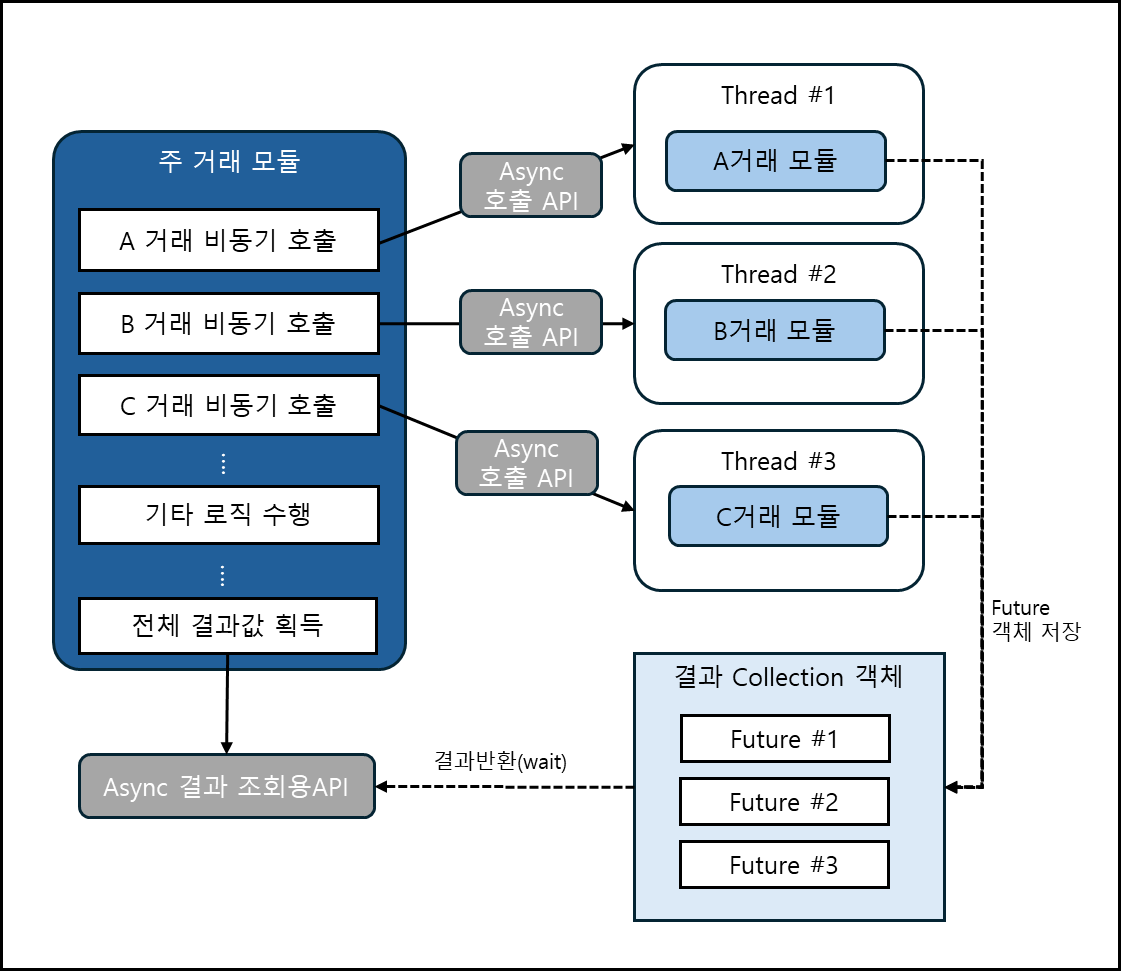 [비동기 연동 서비스 호출 및 결과 반환 흐름]
[비동기 연동 서비스 호출 및 결과 반환 흐름]
위 흐름에서 볼 수 있듯이, 프레임워크에서 제공하는 API 함수를 통해 비동기 호출에 대한 응답 결과를 획득할 수 있습니다.
업무 개발 담당자는 이런 프레임워크 기능을 잘 활용하여 효율적으로 수행되는 업무 프로그램의 처리 로직을 작성하면 됩니다.
이런 프레임워크 기능을 활용하면 전체적인 실시간 응답 시간을 단축하여 고객들에게 보다 만족스러운 금융서비스를 제공할 수 있습니다.
2. 특정 거래의 대량 처리를 위한 센터컷 아키텍처
은행 단말 화면을 통해 처리해야 하는 업무 A가 있습니다.
보통은 담당자가 화면을 통해 정보를 입력하고 처리를 수행하겠지만, 처리해야 하는 건수가 천, 만 단위가 된다면 어떨까요. 담당자는 반복되는 처리 작업을 수행하기 위해 밤을 새야 할 수도 있습니다.
하지만 밤을 새다가 영업일자가 변경되면 곤란해질 수도 있겠죠.
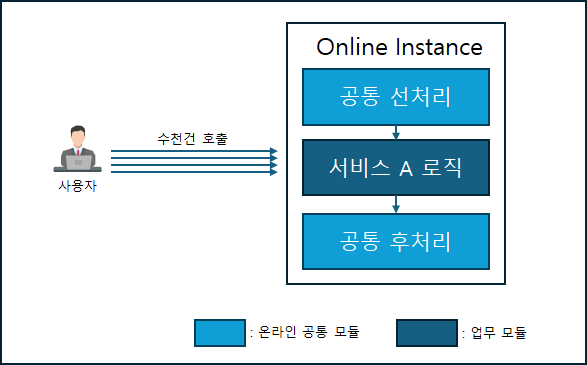 [온라인 단말 프로그램을 통한 다건 처리]
[온라인 단말 프로그램을 통한 다건 처리]
이런 대량 건의 반복 작업을 사람이 일일이 처리하기는 한계가 있으니, 배치 프로그램을 만들어 작성할 수 있을 겁니다.
하지만 여기에도 문제가 있습니다. 온라인 로직에 포함된 공통 처리(예: 회계 처리)를 배치용 선후처리에 추가 작성해야 하며, 이미 구현한 서비스 로직 또한 배치용으로 다시 작성해야 하는 번거로움도 발생합니다.
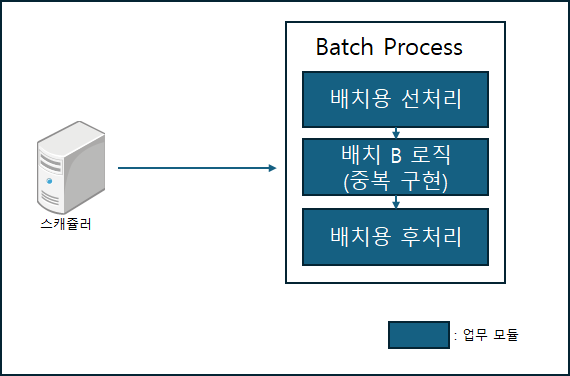 [배치 프로그램을 통한 다건 처리]
[배치 프로그램을 통한 다건 처리]
마치 사용자가 수천 번, 수만 번 화면을 통해 호출한 것처럼 처리할 수는 없을까요.
그렇게 된다면 온라인 프로그램만으로 처리가 가능하므로 프로그램 유지보수 차원에서도 훨씬 간단해지고, 대량 처리도 가능해집니다.
이럴 때 적합한 해결 방안이 센터컷 아키텍처입니다.
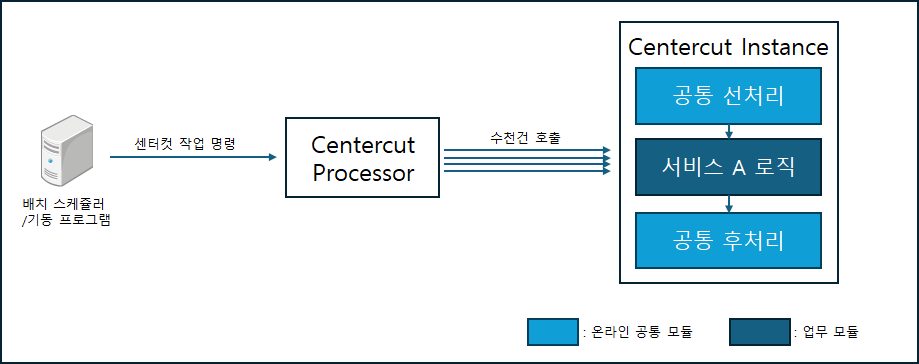 [센터컷을 이용한 다건 처리]
[센터컷을 이용한 다건 처리]
센터컷 아키텍처는 간단히 말해, 센터컷 프로세서에게 작업 명령을 내리면 센터컷 프로세스가 미리 적재된 데이터를 이용하여 사람을 대신해 온라인 서비스를 반복 호출해 주는 기능입니다.
2.1 DevOn Framework Centercut Architecture
DevOn Framework에서 제공하는 센터컷 아키텍처의 전체 그림을 통해 센터컷 동작 방식을 자세히 살펴보도록 하겠습니다.
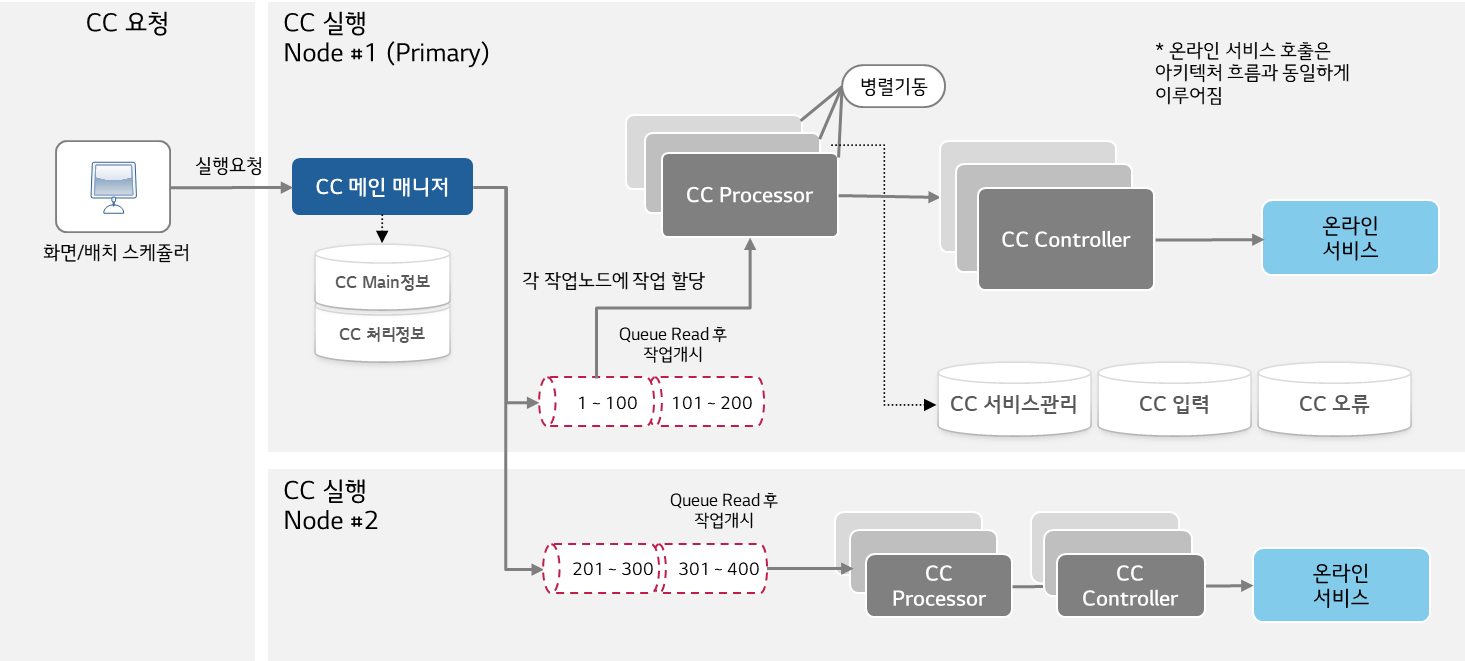 [센터컷을 이용한 다건 처리]
[센터컷을 이용한 다건 처리]
센터컷 작업은 별도의 센터컷 인스턴스에서 동작하며, 여러 인스턴스에서 병렬로 실행되는 센터컷 프로세서에 의해 대량 데이터를 빠른 시간 내에 처리할 수 있습니다.
센터컷 메인 매니저는 각 프로세서에 대한 작업을 제어하여 보다 안정적으로 작업을 수행할 수 있도록 도와줍니다.
센터컷 DB는 별도로 구성하여 기본적인 센터컷 설정, 작업을 수행할 목표 데이터, 병렬 처리의 효율 향상을 위한 그룹 정보 등을 관리합니다.
DevOn Centercut Architecture의 주요 구성요소는 아래와 같습니다.
| 구성요소 | 설명 |
|---|---|
| 센터컷 메인 매니저 | 센터컷 서비스 관리 정보를 조회하여 각 노드에 처리 작업을 할당하고, 센터컷에 설정된 처리 서비스 수에 따른 유량 제어를 수행 |
| 센터컷 Processor | 처리 작업을 명령 받아 처리 대상 데이터를 조회하여 반복 작업을 수행하고, Inbound Controller를 사용하여 본처리 서비스를 호출 |
| 센터컷 컨트롤러 | 온라인 거래와 동일한 흐름으로 거래를 수행하며, 시스템 헤더 정보 세팅 및 선후처리 작업, 트랜잭션 처리, 온라인용 업무 모듈 호출 수행 |
| 센터컷 DB Table | 센터컷 작업 ID·이름·대상 온라인 거래·처리 방식 등 기본 정보, 작업 수행을 위한 업무 요청 데이터, 그룹 정보 및 집계 정보를 관리 |
2.2 Centercut 작업 순서
Centercut으로 대량 처리를 수행하기 위해서는 다음과 같은 작업들이 수행되어야 합니다.
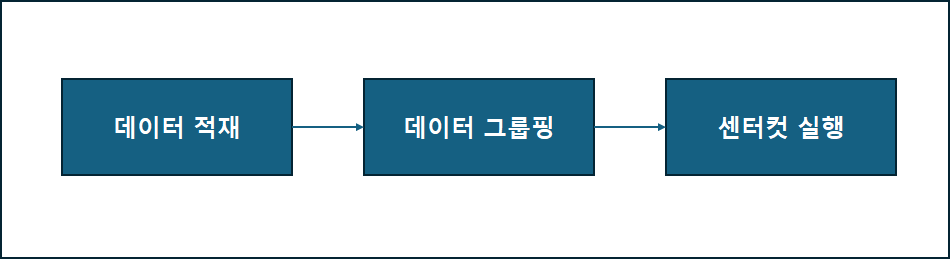
1) 데이터 적재
- 온라인 서비스 호출 시 전달되는 입력 전문의 내용을 별도 Table에 적재하는 작업을 수행
- 보통 타 기관이나 시스템에서 요청된 파일 목록을 데이터화하여 Table에 적재하며, 적재 시 제공되는 API를 사용
2) 데이터 그룹핑
- 여러 Processor에게 작업을 전달하여 병렬로 작업을 수행하기 위해 작업 영역을 그룹핑하는 작업 수행
- 병렬 작업을 위해서만 사용하며, 순차처리는 Skip 가능
3) 센터컷 실행
- 배치 스케줄러나 운영관리를 통해 센터컷 인스턴스에 작업 실행 명령을 전달
- 센터컷은 Main Manager를 생성하여 여러 센터컷 인스턴스에 작업을 할당하고 전체 유량 제어를 수행
2.3 Centercut 모니터링 지원
DevOn Framework는 별도의 운영관리 화면을 통해 센터컷의 처리 진행 상태를 확인할 수 있습니다.
1) 센터컷 메인 작업의 진행 상태 확인
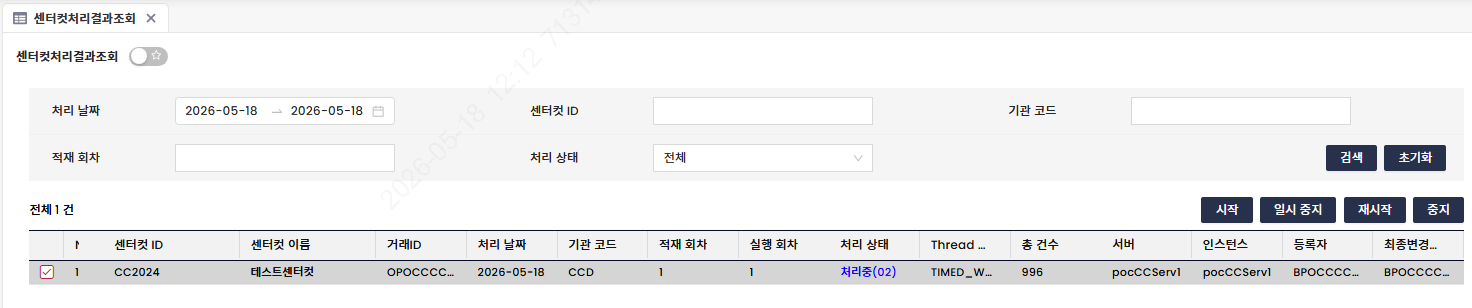
특정 목적을 가진 센터컷을 각 ID로 구분하고 있으며, 해당 센터컷 작업의 진행상태를 확인할 수 있는 화면을 제공합니다.
- 센터컷 ID / 센터컷 이름: 수행 중인 센터컷 ID, 이름
- 거래 ID: 반복 수행해야 할 온라인 서비스 ID
- 처리 상태: 미처리, 처리중, 처리완료 등 센터컷 전체 작업 상태를 표시
- 서버 / 인스턴스: 센터컷 관리자가 실행되고 있는 WAS의 물리적·논리적 위치 표시
2) 센터컷 노드별 진행 상태 확인
앞에서 설명한 센터컷 메인 작업을 화면에서 클릭하면, 하단에 작업을 할당받은 센터컷 노드에서 수행되고 있는 상세 작업 내용을 확인할 수 있습니다.
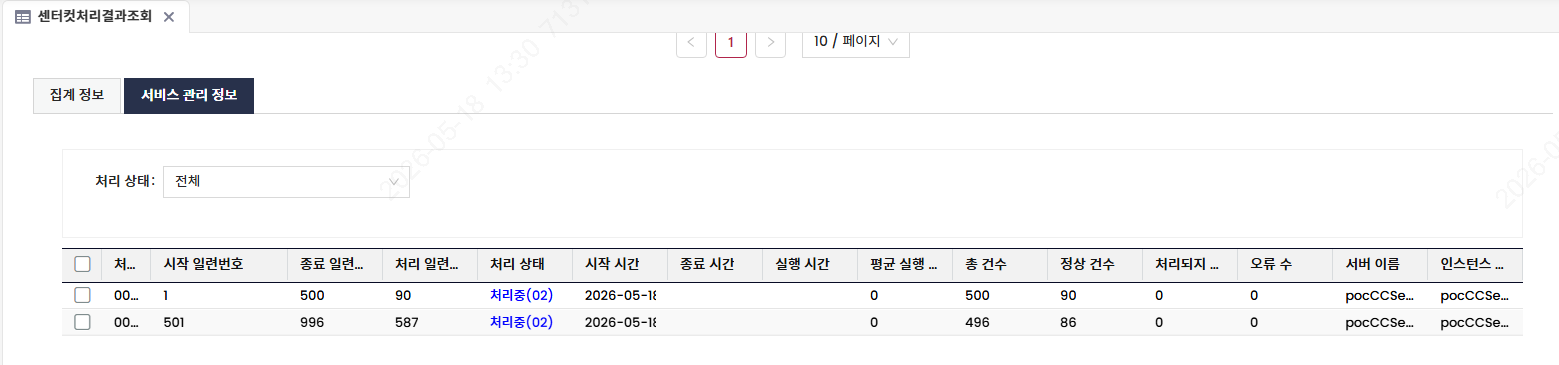
"서비스 관리 정보" 탭을 통해 아래와 같은 센터컷 주요 처리 정보들을 확인할 수 있습니다.
- 처리 서비스 ID: 센터컷 Group 데이터 단위로 할당받아 처리하는 작업의 ID
- 일련번호 정보(시작, 종료, 처리 일련번호): 처리 대상 작업의 일련번호로 할당받은 데이터의 규모와 진행 상태 확인 가능
- 처리 상태: 센터컷 노드별 할당 작업의 처리 상태
- 건수 정보(총건수, 정상, 미처리, 오류 등): 처리해야 할 작업 건수 및 성공·실패 건수 확인 가능
- 서버 / 인스턴스: 해당 작업이 수행되고 있는 WAS의 물리적·논리적 위치 표시
3) 센터컷 처리 상태 확인
"집계 정보" 탭을 통해 센터컷 전체 작업에 대한 집계 정보도 추가로 확인할 수 있습니다.

- 처리 시간 정보: 시작·종료 및 전체 수행 시간을 확인
- 건수 정보: 센터컷 처리 건수 관련 정보
- 금액 정보: 센터컷에서 처리하는 금액의 집계 정보
2.4 DevOn Framework의 Centercut 특징 및 장점
DevOn Framework에서 제공하는 Centercut 기능은 다음과 같은 특징 및 장점을 보유하고 있습니다.
| Centercut 특징 | 설명 | 비고 |
|---|---|---|
| 센터컷 작업의 용이성 | 프레임워크가 센터컷 기반을 지원하므로 업무 파트 담당자는 온라인 서비스 모듈 및 데이터 적재용 배치 모듈 작업에 집중 | 데이터 적재용 API 별도 제공 |
| 센터컷 병렬 처리 | 전체 작업을 제어하는 MainManager와 처리 작업에 집중하는 Processor로 역할을 분리하여, 노드 오류 시 다른 노드로 작업 재개, MainManager 설정에 따른 유량 제어, 여러 Processor에 의한 동시 병렬 처리가 가능 | 가용성·안정성 |
| 센터컷 관리 및 모니터링 제공 | DevOn Framework 운영관리에서 센터컷 전용 화면을 제공하여 성능 세부사항(동시 처리 개수, 그룹당 데이터수) 설정, 기동·중지 등 제어, 진행 상태 모니터링이 가능 | |
| 센터컷 재처리 | 데이터 문제로 오류가 발생한 항목을 확인할 수 있는 화면을 제공하여, 담당자가 데이터 이상을 확인하고 새로운 데이터를 적재해 재처리 가능 | |
| 다양한 처리방식 제공 | 센터컷 데이터를 순서대로 처리해야 하는 경우 순차처리를, 순서와 무관하게 동시 실행이 가능한 경우 병렬처리를 선택하여 사용. 병렬처리를 위해서는 데이터를 나누는(Grouping) 작업을 추가 수행 |
3. 마무리
개인이 앱을 통해 다양한 금융 서비스를 이용하는 것이 하루에도 수십 번씩 반복되는 일상이 된 시대입니다.
은행 앱 하나로 계좌 조회부터 입금·이체·공과금 납부는 물론, 개인 신용 조회와 대출 신청까지 손쉽게 처리할 수 있습니다. 보험 앱에서는 자동차 보험 가입이나 실손보험 청구도 몇 번의 터치만으로 완료됩니다. 나아가 토스나 카카오뱅크와 같은 플랫폼에서는 은행·보험·대출 정보가 하나로 연계되어 기존 금융의 경계를 허무는 새로운 서비스들이 등장하고 있습니다.
이러한 변화는 금융 회사에 새로운 과제를 던져줍니다. 폭발적으로 증가한 실시간 대용량 요청을 안정적으로 처리하면서도 고객이 체감하는 응답 속도와 서비스 품질을 유지해야 한다는 것입니다.
결국 이 모든 것의 출발점은 시스템의 근간을 이루는 프레임워크입니다. 얼마나 견고한 기본기를 갖추고 있는지, 얼마나 유연하게 요구사항을 수용할 수 있는지가 서비스의 완성도를 결정짓습니다. 빠른 응답, 높은 안정성, 대용량 처리 능력을 두루 갖춘 프레임워크를 선택하는 것은 단순한 기술적 결정이 아닌, 고객 신뢰와 시장 경쟁력을 좌우하는 전략적 선택입니다.